Stage 1: /title-to-harness
The user begins with a research title and a short background note. The Agent Skill's job is not to write a proposal. It identifies the paper type, asks about the critical gaps, and generates a structured research harness.
User invocation
Use $distilled-pi
/title-to-harness
Title:
Can Small Language Models Learn to Self-Correct Through Synthetic Critiques?
Optional context:
I want to test whether 1B-3B open-source language models can acquire genuine self-correction behavior from critiques generated by stronger models, rather than merely learning critique-style answer rewriting.
Important:
When the final harness markdown is generated, please save it directly as a Markdown file named `research-harness.md`.
Step 0
The AI performs title triage first
The AI classifies the title as a Research Paper with High confidence.
Key warning: self-correction is a dangerous term. If it is not operationalized, reviewers may interpret it as a stronger capability claim than the experiment can support.
Step 1
The AI asks only five broad intake questions
- Core claim: what is the strongest defensible claim?
- Operational definition: what counts as genuine self-correction, and what does not?
- Strongest baseline: which baseline is most likely to kill the project?
- Minimum evidence path: what is the smallest experiment, ablation, and diagnostic path?
- Falsification condition: what result would force the user to stop using the strong claim?
User
What the user answered
Claim
The user does not defend "robust self-correction." The safer claim is that synthetic critiques provide value beyond corrected-answer supervision under specific diagnostic conditions.
Definition
Self-correction requires sensitivity to critique correctness, partial transfer to unseen error types, and behavior changes when critique quality changes.
Baseline
The most dangerous baseline is answer-only finetuning, because it directly tests whether critique text adds useful information.
Falsification
If answer-only finetuning matches critique training, critique corruption has little effect, or gains disappear on unseen error types, the project must stop using "learn to self-correct."
Decision
The AI runs an Answer Quality Check
| Dimension |
Status |
Reason |
| Core claim |
Clear |
The claim has been narrowed from strong self-correction to critique-content dependence. |
| Novelty path |
Clear |
The novelty is diagnostic empirical analysis, not simple method novelty. |
| Strongest baseline |
Clear |
Answer-only finetuning is explicitly identified as the most dangerous baseline. |
| Implementation details |
Partial |
Model family, optimizer, dataset size, and metric thresholds are not fixed, but they do not block a first harness. |
Decision: Proceed to first harness. No targeted follow-up needed.
Stage 1 output
The AI generates and saves research-harness.md. The important sections are:
Research Question
Operational Definition
Core Hypotheses
Baselines
Ablations
Falsification Conditions
Next 7-Day Plan
## 6. Operational Definition
For this project, genuine self-correction means that a model:
- improves initially incorrect answers after receiving critique information;
- is sensitive to whether the critique is correct, generic, unrelated, or misleading;
- transfers at least partially to unseen error types;
- changes behavior when critique quality changes.
The safe operational label for early experiments is critique-conditioned correction behavior, not robust self-correction.
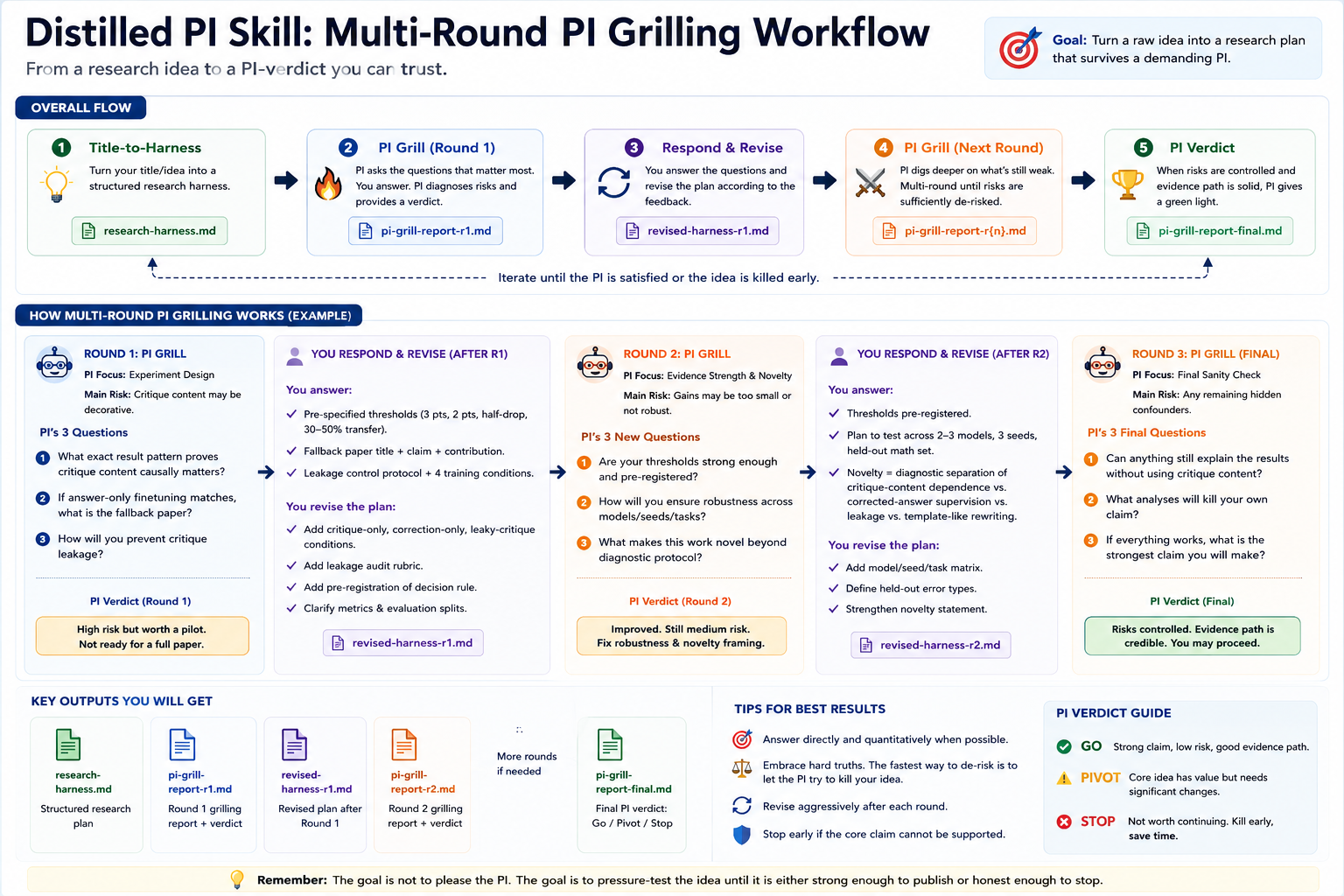
Stage 2: /pi-grill
The user provides research-harness.md as the source of truth. The Agent Skill does not brainstorm from scratch. It simulates a real PI meeting and focuses on the questions most likely to reshape the project.
User invocation
/pi-grill
I am providing the research-harness.md generated by /title-to-harness.
Please act as a demanding PI who is blunt because they want to protect the student from wasting months on a weak claim.
Rules:
- Ask only the 2-3 questions that matter most.
- Do not ask checklist questions.
- Focus on claim validity, novelty, evidence, falsification, and fallback contribution.
- Critique first, then provide a repair path.
- Optimize for finding the fastest way to kill or substantially reshape the project.
When the final report is generated:
- Save it as pi-grill-report.md
- Include PI Focus, Research Risk Heatmap, and PI Verdict.
Diagnosis
The AI chooses one PI Focus
PI Focus: Experiment design
Main danger: if the ablation matrix cannot prove critique-content dependence, the project collapses into an answer-only supervision variant.
Round 1
The AI asks only three decisive questions
- Threshold question: what exact result pattern proves that critique content causally matters, and what threshold makes it non-trivial?
- Fallback question: if answer-only finetuning matches critique training, what is the paper's title and contribution the next day?
- Leakage question: how will the user prevent GPT-4-level critiques from leaking corrected reasoning and making the experiment trivial?
These questions attack distinct dimensions: experiment design, fallback contribution, and evidence validity. They do not repeat the same weakness.
User
How the user answered
- Provisional thresholds: 3 absolute points, 2 absolute points, half-drop under corrupted critiques, and 30-50% transfer.
- Fallback title: Synthetic Critiques Mostly Behave Like Corrected-Answer Supervision for Small Language Models.
- Leakage control: critique-only, correction-only, critique-plus-correction, and leaky-critique conditions.
Important refinement: these thresholds are provisional and should be adjusted based on pilot variance. They should not become fixed Agent Skill-level rules across tasks, datasets, or model families.
Stage 2 output
The AI generates and saves pi-grill-report.md. The core conclusion:
PI's Main Concern
The project must prove a causal contribution from valid critique content, not merely show that corrected-answer supervision works.
PI Verdict
Ready for a pilot experiment. Not ready for a full paper draft. The project is currently an empirical diagnostic paper, not a method paper.
Research Risk Heatmap
| Risk Type |
Level |
Reason |
| Claim Risk |
HIGH |
The title still implies robust self-correction, which the pilot may not support. |
| Novelty Risk |
MEDIUM |
The method itself is not the novelty; the diagnostic protocol is. |
| Experiment Risk |
MEDIUM |
The ablation plan is strong, but threshold rules must be calibrated against pilot variance. |
| Execution Risk |
MEDIUM |
Non-leaky critiques and meaningful misleading critiques are difficult to construct cleanly. |
| Publication Risk |
MEDIUM |
Positive or negative results can both matter if the paper is framed as diagnostic empirical analysis. |
What the User Gets
research-harness.md
Turns a vague title into an inspectable research skeleton. The key improvement is the Operational Definition, which narrows self-correction into testable critique-conditioned correction behavior.
pi-grill-report.md
Stress-tests the harness and returns the most dangerous questions, a risk heatmap, a repair plan, and a PI verdict.
Final judgment from this example: the project is worth a pilot experiment, but it is not ready for a full paper draft, and it should not use the strong self-correction claim until the diagnostics pass.
How to Reproduce This Flow
1. Run /title-to-harness first
Use $distilled-pi
/title-to-harness
Title:
<your research title>
Optional context:
<your short background, concern, or idea>
2. Answer the broad intake questions
Focus on claim, definition, baseline, minimum evidence path, and falsification condition. Implementation details can remain as unknowns in the first harness.
3. Save the generated harness
Filename: research-harness.md
4. Then run /pi-grill
Use $distilled-pi
/pi-grill
I am providing the research-harness.md generated by /title-to-harness.
<paste research-harness.md here>
5. Answer the Round 1 PI questions
If the answers are strong enough, the AI skips Round 2 and directly generates the final repair synthesis and pi-grill-report.md.